You can access the full course here: Convolutional Neural Networks for Image Classification
Table of contents
Intro to Image Recognition
Let’s get started by learning a bit about the topic itself. Image recognition is, at its heart, image classification so we will use these terms interchangeably throughout this course. We see images or real-world items and we classify them into one (or more) of many, many possible categories. The categories used are entirely up to use to decide. For example, we could divide all animals into mammals, birds, fish, reptiles, amphibians, or arthropods. Alternatively, we could divide animals into carnivores, herbivores, or omnivores. Perhaps we could also divide animals into how they move such as swimming, flying, burrowing, walking, or slithering. There are potentially endless sets of categories that we could use.
Among categories, we divide things based on a set of characteristics. When categorizing animals, we might choose characteristics such as whether they have fur, hair, feathers, or scales. Maybe we look at the shape of their bodies or go more specific by looking at their teeth or how their feet are shaped. Once again, we choose there are potentially endless characteristics we could look for.
Analogies aside, the main point is that in order for classification to work, we have to determine a set of categories into which we can class the things we see and the set of characteristics we use to make those classifications. This allows us to then place everything that we see into one of the categories or perhaps say that it belongs to none of the categories. The more categories we have, the more specific we have to be. It’s easier to say something is either an animal or not an animal but it’s harder to say what group of animals an animal may belong to. However complicated, this classification allows us to not only recognize things that we have seen before, but also to place new things that we have never seen. Good image recognition models will perform well even on data they have never seen before (or any machine learning model, for that matter).
How do we Perform Image Recognition?
We do a lot of this image classification without even thinking about it. For starters, we choose what to ignore and what to pay attention to. This actually presents an interesting part of the challenge: picking out what’s important in an image. We see everything but only pay attention to some of that so we tend to ignore the rest or at least not process enough information about it to make it stand out. Knowing what to ignore and what to pay attention to depends on our current goal. For example, if we were walking home from work, we would need to pay attention to cars or people around us, traffic lights, street signs, etc. but wouldn’t necessarily have to pay attention to the clouds in the sky or the buildings or wildlife on either side of us. On the other hand, if we were looking for a specific store, we would have to switch our focus to the buildings around us and perhaps pay less attention to the people around us.
The same thing occurs when asked to find something in an image. We decide what features or characteristics make up what we are looking for and we search for those, ignoring everything else. This is easy enough if we know what to look for but it is next to impossible if we don’t understand what the thing we’re searching for looks like.
This brings to mind the question: how do we know what the thing we’re searching for looks like? There are two main mechanisms: either we see an example of what to look for and can determine what features are important from that (or are told what to look for verbally) or we have an abstract understanding of what we’re looking for should look like already. For example, if you’ve ever played “Where’s Waldo?”, you are shown what Waldo looks like so you know to look out for the glasses, red and white striped shirt and hat, and the cane. To the uninitiated, “Where’s Waldo?” is a search game where you are looking for a particular character hidden in a very busy image. I’d definitely recommend checking it out. However, if we were given an image of a farm and told to count the number of pigs, most of us would know what a pig is and wouldn’t have to be shown. That’s because we’ve memorized the key characteristics of a pig: smooth pink skin, 4 legs with hooves, curly tail, flat snout, etc. We don’t need to be taught because we already know.
This logic applies to almost everything in our lives. We learn fairly young how to classify things we haven’t seen before into categories that we know based on features that are similar to things within those categories. If we come across something that doesn’t fit into any category, we can create a new category. For example, there are literally thousands of models of cars; more come out every year. However, we don’t look at every model and memorize exactly what it looks like so that we can say with certainty that it is a car when we see it. We know that the new cars look similar enough to the old cars that we can say that the new models and the old models are all types of car.
By now, we should understand that image recognition is really image classification; we fit everything that we see into categories based on characteristics, or features, that they possess. We’re intelligent enough to deduce roughly which category something belongs to, even if we’ve never seen it before. If something is so new and strange that we’ve never seen anything like it and it doesn’t fit into any category, we can create a new category and assign membership within that. The next question that comes to mind is: how do we separate objects that we see into distinct entities rather than seeing one big blur?
The somewhat annoying answer is that it depends on what we’re looking for. If we look at an image of a farm, do we pick out each individual animal, building, plant, person, and vehicle and say we are looking at each individual component or do we look at them all collectively and decide we see a farm? Okay, let’s get specific then. Let’s say we aren’t interested in what we see as a big picture but rather what individual components we can pick out. How do we separate them all?
The key here is in contrast. Generally, we look for contrasting colours and shapes; if two items side by side are very different colours or one is angular and the other is smooth, there’s a good chance that they are different objects. Although this is not always the case, it stands as a good starting point for distinguishing between objects.
Coming back to the farm analogy, we might pick out a tree based on a combination of browns and greens: brown for the trunk and branches and green for the leaves. Of course this is just a generality because not all trees are green and brown and trees come in many different shapes and colours but most of us are intelligent enough to be able to recognize a tree as a tree even if it looks different. We could find a pig due to the contrast between its pink body and the brown mud it’s playing in. We could recognize a tractor based on its square body and round wheels. This is why colour-camouflage works so well; if a tree trunk is brown and a moth with wings the same shade of brown as tree sits on the tree trunk, it’s difficult to see the moth because there is no colour contrast.
Another amazing thing that we can do is determine what object we’re looking at by seeing only part of that object. This is really high level deductive reasoning and is hard to program into computers. This is one of the reasons it’s so difficult to build a generalized artificial intelligence but more on that later. As long as we can see enough of something to pick out the main distinguishing features, we can tell what the entire object should be. For example, if we see only one eye, one ear, and a part of a nose and mouth, we know that we’re looking at a face even though we know most faces should have two eyes, two ears, and a full mouth and nose.
Although we don’t necessarily need to think about all of this when building an image recognition machine learning model, it certainly helps give us some insight into the underlying challenges that we might face. If nothing else, it serves as a preamble into how machines look at images. The main problem is that we take these abilities for granted and perform them without even thinking but it becomes very difficult to translate that logic and those abilities into machine code so that a program can classify images as well as we can. This is just the simple stuff; we haven’t got into the recognition of abstract ideas such as recognizing emotions or actions but that’s a much more challenging domain and far beyond the scope of this course.
How do Machines Interpret Images?
The previous topic was meant to get you thinking about how we look at images and contrast that against how machines look at images. We’ll see that there are similarities and differences and by the end, we will hopefully have an idea of how to go about solving image recognition using machine code.
Let’s start by examining the first thought: we categorize everything we see based on features (usually subconsciously) and we do this based on characteristics and categories that we choose. The number of characteristics to look out for is limited only by what we can see and the categories are potentially infinite. This is different for a program as programs are purely logical. As of now, they can only really do what they have been programmed to do which means we have to build into the logic of the program what to look for and which categories to choose between.
This is a very important notion to understand: as of now, machines can only do what they are programmed to do. If we build a model that finds faces in images, that is all it can do. It won’t look for cars or trees or anything else; it will categorize everything it sees into a face or not a face and will do so based on the features that we teach it to recognize. This means that the number of categories to choose between is finite, as is the set of features we tell it to look for. We can tell a machine learning model to classify an image into multiple categories if we want (although most choose just one) and for each category in the set of categories, we say that every input either has that feature or doesn’t have that feature. Machine learning helps us with this task by determining membership based on values that it has learned rather than being explicitly programmed but we’ll get into the details later.
Often the inputs and outputs will look something like this:
Input: [ 1 1 0 0 0 1 0 0 1 0 ]
Output: [ 0 0 1 0 0 ]
In the above example, we have 10 features. A 1 means that the object has that feature and a 0 means that it does not so this input has features 1, 2, 6, and 9 (whatever those may be). We can 5 categories to choose between. A 1 in that position means that it is a member of that category and a 0 means that it is not so our object belongs to category 3 based on its features. This form of input and output is called one-hot encoding and is often seen in classification models. Realistically, we don’t usually see exactly 1s and 0s (especially in the outputs). We should see numbers close to 1 and close to 0 and these represent certainties or percent chances that our outputs belong to those categories. For example, if the above output came from a machine learning model, it may look something more like this:
[ 0.01 0.02 0.95 0.01 0.01]
This means that there is a 1% chance the object belongs to the 1st, 4th, and 5th categories, a 2% change it belongs to the 2nd category, and a 95% chance that it belongs to the 3rd category. It can be nicely demonstrated in this image:

How do Machines Interpret Images?
This provides a nice transition into how computers actually look at images. To a computer, it doesn’t matter whether it is looking at a real-world object through a camera in real time or whether it is looking at an image it downloaded from the internet; it breaks them both down the same way. Essentially, in image is just a matrix of bytes that represent pixel values. When it comes down to it, all data that machines read whether it’s text, images, videos, audio, etc. is broken down into a list of bytes and is then interpreted based on the type of data it represents.
For images, each byte is a pixel value but there are up to 4 pieces of information encoded for each pixel. Grey-scale images are the easiest to work with because each pixel value just represents a certain amount of “whiteness”. Because they are bytes, values range between 0 and 255 with 0 being the least white (pure black) and 255 being the most white (pure white). Everything in between is some shade of grey. With colour images, there are additional red, green, and blue values encoded for each pixel (so 4 times as much info in total). Each of those values is between 0 and 255 with 0 being the least and 255 being the most. If an image sees a bunch of pixels with very low values clumped together, it will conclude that there is a dark patch in the image and vice versa.
Below is a very simple example. An image of a 1 might look like this:

And have this as the pixel values:
[[255, 255, 255, 255, 255],
[255, 255, 0, 255, 255],
[255, 255, 0, 255, 255],
[255, 255, 0, 255, 255],
[255, 255, 255, 255, 255]]
This is definitely scaled way down but you can see a clear line of black pixels in the middle of the image data (0) with the rest of the pixels being white (255).
Images have 2 dimensions to them: height and width. These are represented by rows and columns of pixels, respectively. In this way, we can map each pixel value to a position in the image matrix (2D array so rows and columns). Machines don’t really care about the dimensionality of the image; most image recognition models flatten an image matrix into one long array of pixels anyway so they don’t care about the position of individual pixel values. Rather, they care about the position of pixel values relative to other pixel values. They learn to associate positions of adjacent, similar pixel values with certain outputs or membership in certain categories. In the above example, a program wouldn’t care that the 0s are in the middle of the image; it would flatten the matrix out into one long array and say that, because there are 0s in certain positions and 255s everywhere else, we are likely feeding it an image of a 1. The same can be said with coloured images. If a model sees pixels representing greens and browns in similar positions, it might think it’s looking at a tree (if it had been trained to look for that, of course).
This is also how image recognition models address the problem of distinguishing between objects in an image; they can recognize the boundaries of an object in an image when they see drastically different values in adjacent pixels. A machine learning model essentially looks for patterns of pixel values that it has seen before and associates them with the same outputs. It does this during training; we feed images and the respective labels into the model and over time, it learns to associate pixel patterns with certain outputs. If a model sees many images with pixel values that denote a straight black line with white around it and is told the correct answer is a 1, it will learn to map that pattern of pixels to a 1.
This is great when dealing with nicely formatted data. If we feed a model a lot of data that looks similar then it will learn very quickly. The problem then comes when an image looks slightly different from the rest but has the same output. Consider again the image of a 1. It could be drawn at the top or bottom, left or right, or center of the image. It could have a left or right slant to it. It could look like this: 1 or this l. This is a big problem for a poorly-trained model because it will only be able to recognize nicely-formatted inputs that are all of the same basic structure but there is a lot of randomness in the world. We need to be able to take that into account so our models can perform practically well. This is why we must expose a model to as many different kinds of inputs as possible so that it learns to recognize general patterns rather than specific ones. There are tools that can help us with this and we will introduce them in the next topic.
Hopefully by now you understand how image recognition models identify images and some of the challenges we face when trying to teach these models. Models can only look for features that we teach them to and choose between categories that we program into them. To machines, images are just arrays of pixel values and the job of a model is to recognize patterns that it sees across many instances of similar images and associate them with specific outputs. We need to teach machines to look at images more abstractly rather than looking at the specifics to produce good results across a wide domain. Next up we will learn some ways that machines help to overcome this challenge to better recognize images. In the meantime, though, consider browsing our article on just what sort of job opportunities await you should you pursue these exciting Python topics!
Transcript
What is up, guys? Welcome to the first tutorial in our image recognition course. This is also the very first topic, and is just going to provide a general intro into image recognition. Now we’re going to cover two topics specifically here. One will be, “What is image recognition?” and the other will be, “What tools can help us to solve image recognition?”
The first part, which will be this video, will be all about introducing the problem of image recognition, talk about how we solve the problem of image recognition in our day-to-day lives, and then we’ll go onto explore this from a machine’s point of view. After that, we’ll talk about the tools specifically that machines use to help with image recognition. Specifically, we’ll be looking at convolutional neural networks, but a bit more on that later.
Let’s get started with, “What is image recognition?” Image recognition is seeing an object or an image of that object and knowing exactly what it is. At the very least, even if we don’t know exactly what it is, we should have a general sense for what it is based on similar items that we’ve seen. Essentially, we class everything that we see into certain categories based on a set of attributes. That’s why image recognition is often called image classification, because it’s essentially grouping everything that we see into some sort of a category.
Now the attributes that we use to classify images is entirely up to us. For example, if we’re looking at different animals, we might use a different set of attributes versus if we’re looking at buildings or let’s say cars, for example. If we’re looking at vehicles, we might be taking a look at the shape of the vehicle, the number of windows, the number of wheels, et cetera. If we’re looking at animals, we might take into consideration the fur or the skin type, the number of legs, the general head structure, and stuff like that. It’s entirely up to us which attributes we choose to classify items. And this could be real-world items as well, not necessarily just images.
Now, this allows us to categorize something that we haven’t even seen before. In fact, this is very powerful. We can take a look at something that we’ve literally never seen in our lives, and accurately place it in some sort of a category. We can often see this with animals. I highly doubt that everyone has seen every single type of animal there is to see out there. No doubt there are some animals that you’ve never seen before in your lives. But, you should, by looking at it, be able to place it into some sort of category. You should know that it’s an animal. You should have a general sense for whether it’s a carnivore, omnivore, herbivore, and so on and so forth.
Now, another example of this is models of cars. Now, every single year, there are brand-new models of cars coming out, some which we’ve never seen before. Some look so different from what we’ve seen before, but we recognize that they are all cars. We can take a look again at the wheels of the car, the hood, the windshield, the number of seats, et cetera, and just get a general sense that we are looking at some sort of a vehicle, even if it’s not like a sedan, or a truck, or something like that.
Now, how does this work for us? Well, a lot of the time, image recognition actually happens subconsciously. In fact, we rarely think about how we know what something is just by looking at it. We just kinda take a look at it, and we know instantly kind of what it is. And a big part of this is the fact that we don’t necessarily acknowledge everything that is around us. If we do need to notice something, then we can usually pick it out and define and describe it.
Take, for example, if you’re walking down the street, especially if you’re walking a route that you’ve walked many times. It’s highly likely that you don’t pay attention to everything around you. Maybe there’s stores on either side of you, and you might not even really think about what the stores look like, or what’s in those stores. However, when you go to cross the street, you become acutely aware of the other people around you, of the cars around you, because those are things that you need to notice. In fact, even if it’s a street that we’ve never seen before, with cars and people that we’ve never seen before, we should have a general sense for what to do. The light turns green, we go, if there’s a car driving in front of us, probably shouldn’t walk into it, and so on and so forth.
Now, this kind of process of knowing what something is is typically based on previous experiences. If we’d never come into contact with cars, or people, or streets, we probably wouldn’t know what to do. However, we’ve definitely interacted with streets and cars and people, so we know the general procedure. So, go on a green light, stop on a red light, so on and so forth, and that’s because that’s stuff that we’ve seen in the past. Even if we haven’t seen that exact version of it, we kind of know what it is because we’ve seen something similar before.
Now, sometimes this is done through pure memorization. Maybe we look at a specific object, or a specific image, over and over again, and we know to associate that with an answer. This is just kind of rote memorization. However, the more powerful ability is being able to deduce what an item is based on some similar characteristics when we’ve never seen that item before. And that’s really the challenge.
It’s easy enough to program in exactly what the answer is given some kind of input into a machine. You could just use like a map or a dictionary for something like that. However, the challenge is in feeding it similar images, and then having it look at other images that it’s never seen before, and be able to accurately predict what that image is. Now, this kind of a problem is actually two-fold. The problem is first deducing that there are multiple objects in your field of vision, and the second is then recognizing each individual object.
So, step number one, how are we going to actually recognize that there are different objects around us? Typically, we do this based on borders that are defined primarily by differences in color. This makes sense. If we’ve seen something that camouflages into something else, probably the colors are very similar, so it’s just hard to tell them apart, it’s hard to place a border on one specific item. However, if you see, say, a skyscraper outlined against the sky, there’s usually a difference in color. It’s very easy to see the skyscraper, maybe, let’s say, brown, or black, or gray, and then the sky is blue. So there’s that sharp contrast in color, therefore we can say, ‘Okay, there’s obviously something in front of the sky.’
Now, again, another example is it’s easy to see a green leaf on a brown tree, but let’s say we see a black cat against a black wall. We might not even be able to tell it’s there at all, unless it opens its eyes, or maybe even moves. Now, we don’t necessarily need to look at every single part of an image to know what some part of it is. Take, for example, if you have an image of a landscape, okay, so there’s maybe some trees in the background, there’s a house, there’s a farm, or something like that, and someone asks you to point out the house. Well, you don’t even need to look at the entire image, it’s just as soon as you see the bit with the house, you know that there’s a house there, and then you can point it out.
This is even more powerful when we don’t even get to see the entire image of an object, but we still know what it is. Take, for example, an image of a face. Let’s say we’re only seeing a part of a face. Specifically, we only see, let’s say, one eye and one ear. But we still know that we’re looking at a person’s face based on the color, the shape, the spacing of the eye and the ear, and just the general knowledge that a face, or at least a part of a face, looks kind of like that. Our brain fills in the rest of the gap, and says, ‘Well, we’ve seen faces, a part of a face is contained within this image, therefore we know that we’re looking at a face.’
That’s, again, a lot more difficult to program into a machine because it may have only seen images of full faces before, and so it gets a part of a face, and it doesn’t know what to do. No longer are we looking at two eyes, two ears, the mouth, et cetera. We’re only looking at a little bit of that.
Now, before we talk about how machines process this, I’m just going to kind of summarize this section, we’ll end it, and then we’ll cover the machine part in a separate video, because I do wanna keep things a bit shorter, there’s a lot to process here. So some of the key takeaways are the fact that a lot of this kinda image recognition classification happens subconsciously. We just look at an image of something, and we know immediately what it is, or kind of what to look out for in that image. Obviously this gets a bit more complicated when there’s a lot going on in an image.
Also, image recognition, the problem of it is kinda two-fold. The first is recognizing where one object ends and another begins, so kinda separating out the object in an image, and then the second part is actually recognizing the individual pieces of an image, putting them together, and recognizing the whole thing. Also, know that it’s very difficult for us to program in the ability to recognize a whole part of something based on just seeing a single part of it, but it’s something that we are naturally very good at.
Okay, so, think about that stuff, stay tuned for the next section, which will kind of talk about how machines process images, and that’ll give us insight into how we’ll go about implementing the model. Okay, so thanks for watching, we’ll see you guys in the next one.
What’s up guys? Welcome to the second tutorial in our image recognition course. Here we’re going to continue on with how image recognition works, but we’re going to explore it from a machine standpoint now. We just finished talking about how humans perform image recognition or classification, so we’ll compare and contrast this process in machines.
For starters, contrary to popular belief, machines do not have infinite knowledge of what everything they see is. So, let’s say we’re building some kind of program that takes images or scans its surroundings. Well, it’s going to take in all that information, and it may store it and analyze it, but it doesn’t necessarily know what everything it sees it. It might not necessarily be able to pick out every object.
Machines only have knowledge of the categories that we have programmed into them and taught them to recognize. And, actually, this goes beyond just image recognition, machines, as of right now at least, can only do what they’re programmed to do. So this means, if we’re teaching a machine learning image recognition model, to recognize one of 10 categories, it’s never going to recognize anything else, outside of those 10 categories.
Now, a simple example of this, is creating some kind of a facial recognition model, and its only job is to recognize images of faces and say, “Yes, this image contains a face,” or, “no, it doesn’t.” So basically, it classifies everything it sees into a face or not a face. Now, this means that even the most sophisticated image recognition models, the best face recognition models will not recognize everything in that image. It’s never going to take a look at an image of a face, or it may be not a face, and say, “Oh, that’s actually an airplane,” or, “that’s a car,” or, “that’s a boat or a tree.”
It’s just going to say, “No, that’s not a face,” okay? Because that’s all it’s been taught to do. It’s classifying everything into one of those two possible categories, okay? So even if something doesn’t belong to one of those categories, it will try its best to fit it into one of the categories that it’s been trained to do. So, essentially, it’s really being trained to only look for certain objects and anything else, just, it tries to shoehorn into one of those categories, okay? So that’s a very important takeaway, is that if we want a model to recognize something, we have to program it to recognize that, okay? Otherwise, it may classify something into some other category or just ignore it completely.
Now, to a machine, we have to remember that an image, just like any other data, is simply an array of bytes. So it’s really just an array of data. It doesn’t look at an incoming image and say, “Oh, that’s a two,” or “that’s an airplane,” or, “that’s a face.” It’s just an array of values. Even images – which are technically matrices, there they have columns and rows, they are essentially rows of pixels, these are actually flattened out when a model processes these images.
Generally speaking, we flatten it all into one long array of bytes. So, I say bytes because typically the values are between zero and 255, okay? So that’s a byte range, but, technically, if we’re looking at color images, each of the pixels actually contains additional information about red, green, and blue color values. Lucky for us, we’re only really going to be working with black and white images, so this problem isn’t quite as much of a problem. But realistically, if we’re building an image recognition model that’s to be used out in the world, it does need to recognize color, so the problem becomes four times as difficult.
Now, if an image is just black or white, typically, the value is simply a darkness value. I guess this actually should be a whiteness value because 255, which is the highest value as a white, and zero is black. And, that means anything in between is some shade of gray, so the closer to zero, the lower the value, the closer it is to black. And, the higher the value, closer to 255, the more white the pixel is.
Now, this is the same for red, green, and blue color values, as well. If we get a 255 in a red value, that means it’s going to be as red as it can be. If we get 255 in a blue value, that means it’s gonna be as blue as it can be. But, of course, there are combinations. So, for example, if we get 255 red, 255 blue, and zero green, we’re probably gonna have purple because it’s a lot of red, a lot of blue, and that makes purple, okay? So this is kind of how we’re going to get these various color values encoded into our images.
Now, machines don’t really care about seeing an image as a whole, it’s a lot of data to process as a whole anyway, so actually, what ends up happening is these image recognition models often make these images more abstract and smaller, but we’ll get more into that later. To process an image, they simply look at the values of each of the bytes and then look for patterns in them, okay?
So if we feed an image of a two into a model, it’s not going to say, “Oh, well, okay, I can see a two.” It’s just gonna see all of the pixel value patterns and say, “Oh, I’ve seen those before “and I’ve associated with it, associated those with a two. “So we’ll probably do the same this time,” okay? So they’re essentially just looking for patterns of similar pixel values and associating them with similar patterns they’ve seen before. In this way, image recognition models look for groups of similar byte values across images so that they can place an image in a specific category.
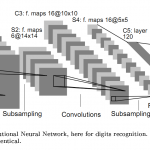
Again, coming back to the concept of recognizing a two, because we’ll actually be dealing with digit recognition, so zero through nine, we essentially will teach the model to say, “‘Kay, we’ve seen this similar pattern in twos. “We’ve seen this pattern in ones,” et cetera. So when it sees a similar patterns, it says, “Okay, well, we’ve seen those patterns “and associated it with a specific category before, “so we’ll do the same.”
Now, I should say actually, on this topic of categorization, it’s very, very rarely going to be the case that the model is 100% certain an image belongs to any category, okay? That’s why these outputs are very often expressed as percentages. So it might be, let’s say, 98% certain an image is a one, but it also might be, you know, 1% certain it’s a seven, maybe .5% certain it’s something else, and so on, and so forth. So it’s very, very rarely 100% it will, you know, we can get very close to 100% certainty, but we usually just pick the higher percent and go with that.
Now, an example of a color image would be, let’s say, a high green and high brown values in adjacent bytes, may suggest an image contains a tree, okay? Now, if many images all have similar groupings of green and brown values, the model may think they all contain trees. So it will learn to associate a bunch of green and a bunch of brown together with a tree, okay? So this is maybe an image recognition model that recognizes trees or some kind of, just everyday objects.
Now, the unfortunate thing is that can be potentially misleading. There are plenty of green and brown things that are not necessarily trees, for example, what if someone is wearing a camouflage tee shirt, or camouflage pants? Well, that’s definitely not a tree, that’s a person, but that’s kind of the point of wearing camouflage is to fool things or people into thinking that they are something else, in this case, a tree, okay? So really, the key takeaway here is that machines will learn to associate patterns of pixels, rather than an individual pixel value, with certain categories that we have taught it to recognize, okay?
Now, we can see a nice example of that in this picture here. So, there’s a lot going on in this image, even though it may look fairly boring to us. There’s the decoration on the wall. There’s the lamp, the chair, the TV, the couple of different tables. There’s a vase full of flowers. There’s a picture on the wall and there’s obviously the girl in front. And, the girl seems to be the focus of this particular image.
Now, we are kind of focusing around the girl’s head, but there’s also, a bit of the background in there, there’s also, you got to think about her hair, contrasted with her skin. There’s also a bit of the image, that kind of picture on the wall, and so on, and so forth. So there may be a little bit of confusion. It’s not 100% girl and it’s not 100% anything else. And, that’s why, if you look at the end result, the machine learning model, this is 94% certain that it contains a girl, okay? It’s, for a reason, 2% certain it’s the bouquet or the clock, even though those aren’t directly in the little square that we’re looking at, and there’s a 1% chance it’s a sofa.
Now, I know these don’t add up to 100%, it’s actually 101%. But, you’ve got to take into account some kind of rounding up. Also, this definitely demonstrates how a bigger image is broken down into many, many smaller images and ultimately is categorized into one of these categories. So, in this case, we’re maybe trying to categorize everything in this image into one of four possible categories, either it’s a sofa, clock, bouquet, or a girl. And, in this case, what we’re looking at, it’s quite certain it’s a girl, and only a lesser bit certain it belongs to the other categories, okay?
So again, remember that image classification is really image categorization. Machines can only categorize things into a certain subset of categories that we have programmed it to recognize, and it recognizes images based on patterns in pixel values, rather than focusing on any individual pixel, ‘kay? So when we come back, we’ll talk about some of the tools that will help us with image recognition, so stay tuned for that.
Otherwise, thanks for watching! See you guys in the next one!
Interested in continuing? Check out the full Convolutional Neural Networks for Image Classification course, which is part of our Machine Learning Mini-Degree.